Machine Learning in Marketing Research: Insights Through Advanced Profiling, Synthetic Data and Emotion Analysis
In our previous blog on machine learning titled “Machine Learning in Marketing Research,” we explored how machine learning significantly contributes to identifying fraudulent responses and detecting logical inconsistencies in survey data. This blog continues our in-depth discussion on machine learning, where we will investigate its advanced applications that radically transform our approach to understanding and utilizing market data.
As we delve deeper, we will reveal how advanced profiling, the creation of synthetic data, and precise emotion analysis not only enhance our understanding of market trends but also open new doors in the world of marketing research. With these machine learning techniques, we will explore new dimensions in consumer data analysis, enabling a better comprehension of consumer habits and preferences.
Advanced profiling
Machine learning empowers advanced profiling through clustering, a technique that groups similar survey responses based on their characteristics and patterns, unveiling population subgroups and underlying structures. With clustering, ML performs complex analyses that may be challenging for humans, driving exploratory analysis and anomaly detection, which can help us gain a deeper understanding of consumer preferences and perceptions by revealing the relationships between various interrelated attributes.
As the number of responses and attributes increases, clustering becomes more challenging, but the insights it offers are invaluable. To gain a deeper understanding of the clusters, statistical analyses such as descriptive statistics, analysis of variance (ANOVA), and discriminant analysis can be employed. Descriptive statistics involve calculating key metrics like mean, median, standard deviation, minimum, and maximum for each cluster to provide an overview of the central tendencies and variations within the groups, aiding in identifying patterns and trends. ANOVA goes beyond descriptive statistics by conducting statistical tests to determine if there are statistically significant differences in means between two or more clusters. Finally, discriminant analysis is a powerful tool that identifies the variables responsible for the separation between different clusters. Together, these analyses provide a comprehensive and in-depth understanding of the distinct consumer groups, empowering businesses with data-driven decisions and targeted strategies.
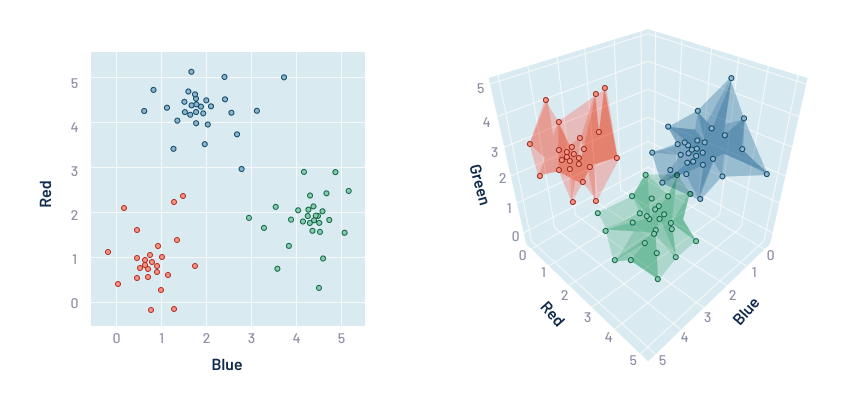
Clustering in Advanced Profiling
Synthetic data
Machine learning also enables the generation of synthetic data that mimics the characteristics and patterns of original data without containing any sensitive information. It serves as a cost-effective alternative for obtaining large volumes of data, especially when data collection is expensive. This process proves valuable in generating more examples of statistically representative data, particularly for demographics with limited numbers (such as males between 18-22), and enables statistical analyses dependent on sample size. Using algorithms that employ encoder Neural Networks (NNs), the original data distribution can be transformed into a latent distribution, which serves as the basis for creating synthetic data through random sampling and decoding.
However, while synthetic data mimics the real data, it may not capture all the nuances, outliers, and complex patterns present in the original dataset. It is crucial to recognize that synthetic data cannot replace the need for actual surveys, as it only complements real data by augmenting and diversifying the dataset, balancing classes, and increasing statistical power. Hence, careful assessment and validation of the quality of synthetic data are essential, and it is imperative to provide appropriate disclaimers when including synthetic data in analyses to understand the implications fully.
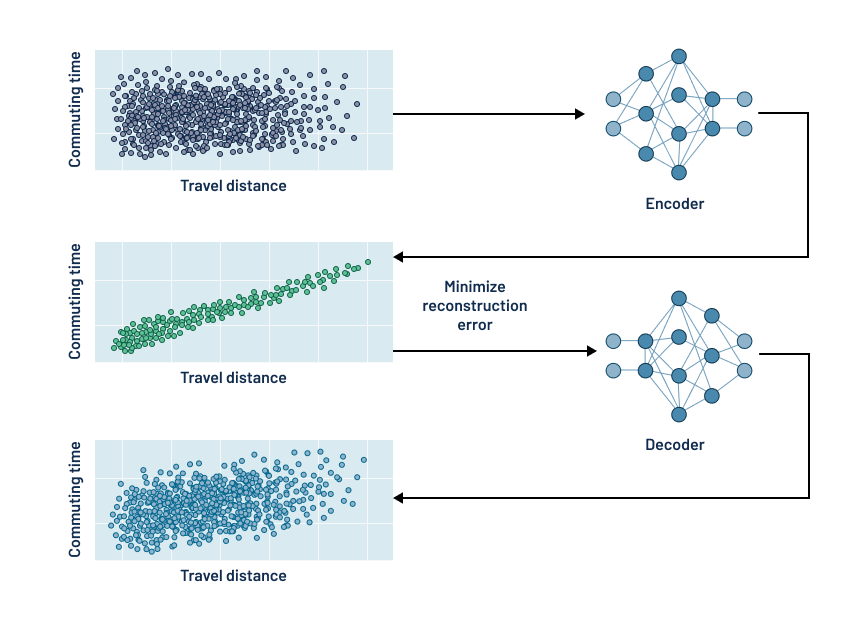
Generating Synthetic Data Example
Sentiment analysis
Machine learning plays a crucial role in facilitating sentiment analysis in marketing research, particularly in evaluating positive and negative sentiments in open-ended survey answers related to products, product parts, and product qualities. The process involves text pre-processing, including tokenization, lemmatization, and removing stopwords, followed by using sentiment lexicons to determine sentiment scores for each word. To enhance context consideration, recurrent neural networks (RNN) and BERT models can be employed, taking into account negation, intensifiers, and even semantics.
Additionally, machine learning enables text clustering by transforming survey responses into numerical vector representations using algorithms like TF-IDF or Word2Vec. Regular clustering techniques are then applied to group similar responses, followed by characterizing the clusters using keywords, word frequency visualizations (word clouds), or thematic grouping. This unsupervised approach allows researchers to gain insights into customer sentiments and preferences by effectively analyzing and organizing open-ended survey responses.

Visualization of Word Frequency
Conclusions
As we conclude our exploration of the role of machine learning in marketing research, it is increasingly clear that this technology brings revolutionary approaches to analyzing and interpreting market data. With advanced techniques such as profiling, creating synthetic data, and emotion analysis, machine learning unveils in-depth insights into consumer habits and preferences.
These innovations open new possibilities for developing more effective strategies and thoughtful business decisions, underpinned by precise and extensive data. Despite existing challenges such as ensuring quality and correct interpretation of data, these techniques offer invaluable worth in the rapidly changing world of market research. We hope this series of blogs has opened new horizons for you and encouraged further exploration and innovation in this fascinating field.
We do it with passion and dedication.
CONSENT TO PERSONAL DATA PROCESSING
I hereby acknowledge and agree with the processing of personal data, which I submit to owner and controller Solviks, programske rešitve in poslovno svetovanje, d.o.o. ((ang. Solviks, software solutions and business consulting, d.o.o) Počehova 59i, 2000 Maribor, Slovenia, e-mail: info@solve-x.net) on the Website.
I hereby acknowledge and agree that the personal data provided is processed for the following purposes:
- marketing purposes relating to offers of products and services;
- sending information about products, services and other activities.
Solviks, d.o.o. is processing name, surname, e-mail.
The legal basis for the processing of personal data is the consent of individual under Article 6(1) of General Data Protection Regulation – GDPR.
I hereby acknowledge that the personal data which I submit will be processed to the extent necessary to achieve the above-mentioned purposes.
I hereby represent that I have been informed about my right to:
- withdraw my consent to personal data processing at any time- GDPR, Article 7;
- right to be informed- GDPR; Article 13;
- obtain access to the personal data held – GDPR, Article 15;
- incorrect, inaccurate or incomplete personal data to be corrected – GDPR, Article 16;
- request that personal data be erased when it is no longer needed or if processing is unlawful – GDPR, Article 17;
- request the restriction or suppression of personal data – GDPR, Article 18;
- receive personal data in a machine-readable format (data in a data format that can be automatically read and processed by a computer) and sent it to another controller – GDPR, Article 20);
- object to the processing of personal data in specific cases – GDPR, Article 21;
- request that decisions based on automated processing concerning or significantly affecting a person and it is based on personal data are made by natural persons, not only by completers – GDPR, Article 22 (automated is only a process of inviting members to participate in surveys);
- object to the transfer of my personal data.
I hereby acknowledge that I can submit a complaint to the Information Commissioner in Slovenia (Dunajska cesta 22, 1000 Ljubljana, e-mail: gp.ip@ip-rs.si, phone: 012309730, Website: www.ip-rs.si).
I hereby acknowledge that personal data requests and any other questions about personal data can be sent to an e-mail: vesna.brlic@solve-x.net or info@solve-x.net.
I hereby represent that I have carefully read all the above provisions and do voluntarily and unequivocally agree with them.